CentOS命令行性能检测工具详解
一、uptime
Uptime命令的显示结果包括服务器已经运行了多长时间,有多少登陆用户和对服务器性能的总体评估(load average)。load average值分别记录了上个1分钟,5分钟和15分钟间隔的负载情况,load average不是一个百分比,而是在队列中等待执行的进程的数量。如果进程要求CPU时间被阻塞(意味着CPU没有时间处理它),load average值将增加。另一方面,如果每个进程都可以立刻得到访问CPU的时间,这个值将减少。
UP kernel下的load average的最佳值是1,这说明每个进程都可以立刻被CPU处理,当然,更低不会有问题,只说明浪费了一部分的资源。但在不同的系统间这个值也是不同的,例如一个单CPU的工作站,load average为1或者2都是可以接受的,而在一个多CPU的系统中这个值应除以物理CPU的个数,假设CPU个数为4,而load average为8或者10,那结果也是在2多点而已。

你可以使用uptime判断一个性能问题是出现在服务器上还是网络上。例如,如果一个网络应用运行性能不理想,运行uptime检查系统负载是否比较高,如果不是这个问题更可能出现在你的网络上。
二、top
Top命令显示了实际CPU使用情况,默认情况下,它显示了服务器上占用CPU的任务信息并且每5秒钟刷新一次。你可以通过多种方式分类它们,包括PID、时间和内存使用情况。
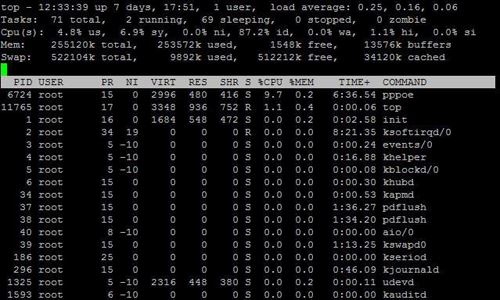
下面是输出值的介绍:
引用
PID:进程标识
USER;进程所有者的用户名
PRI:进程的优先级
NI:nice级别
SIZE:进程占用的内存数量(代码+数据+堆栈)
RSS;进程使用的物理内存数量
SHARE;该进程和其他进程共享内存的数量
STAT:进程的状态:S=休眠状态,R=运行状态,T=停止状态,D=中断休眠状态,Z=僵尸状态
%CPU:共享的CPU使用
%MEM;共享的物理内存
TIME:进程占用CPU的时间
COMMAND:启动任务的命令行(包括参数)
进程的优先级和nice级别
进程优先级是一个决定进程被CPU执行优先顺序的参数,内核会根据需要调整这个值。Nice值是一个对优先权的限制。进程优先级的值不能低于nice值。(nice值越低优先级越高)
进程优先级是无法去手动改变的,只有通过改变nice值去间接的调整进程优先级。如果一个进程运行的太慢了,你可以通过指定一个较低的nice值去为它分配更多的CPU资源。当然,这意味着其他的一些进程将被分配更少的CPU资源,运行更慢一些。Linux支持nice值的范围是19(低优先级)到-20(高优先级),默认的值是0。如果需要改变一个进程的nice值为负数(高优先级),必须使用su命令登陆到root用户。下面是一些调整nice值的命令示例,
以nice值-5开始程序xyz
#nice –n -5 xyz
改变已经运行的程序的nice值
#renice level pid
将pid为2500的进程的nice值改为10
#renice 10 2500
僵尸进程
当一个进程被结束,在它结束之前通常需要用一些时间去完成所有的任务(比如关闭打开的文件),在一个很短的时间里,这个进程的状态为僵尸状态。在进程完成所有关闭任务之后,会向父进程提交它关闭的信息。有些情况下,一个僵尸进程不能关闭它自己,这时这个进程状态就为z(zombie)。不能使用kill命令杀死僵尸进程,因为它已经标志为“dead”。如果你无法摆脱一个僵尸进程,你可以杀死它的父进程,这个僵尸进程也就消失了。然而,如果父进程是init进程,你不能杀死init进程,因为init是一个重要的系统进程,这种情况下你只能通过一次重新启动服务器来摆脱僵尸进程。也必须分析应用为什么会导致僵死?
三、iostat
iostat是sysstat包的一部分。Iostat显示自系统启动后的平均CPU时间(与uptime类似),它也可以显示磁盘子系统的使用情况,iostat可以用来监测CPU利用率和磁盘利用率。
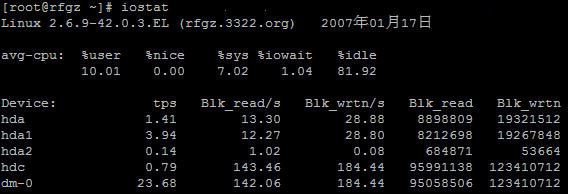
CPU利用率分四个部分:
引用
%user:user level(应用)的CPU占用率情况
%nice:加入nice优先级的user level的CPU占用率情况
%sys:system level(内核)的CPU占用情况
%idle:空闲的CPU资源情况
磁盘占用率有下面几个部分:
引用
Device:块设备名
Tps:设备每秒进行传输的数量(每秒的I/O请求)。多个单独的I/O请求可以被组成一个传输操作,因为一个传输操作可以是不同的容量。
Blk_read/s, Blk_wrtn/s:该设备每秒读写的块的数量。块可能为不同的容量。
Blk_read, Blk_wrtn:自系统启动以来读写的块设备的总量。
块的大小
块可能为不同的容量。块的大小一般为1024、2048、4048byte。可通过tune2fs或dumpe2fs获得:
引用
[root@rfgz ~]# tune2fs -l /dev/hda1|grep 'Block size'
Block size: 4096
[root@rfgz ~]# dumpe2fs -h /dev/hda1|grep 'Block size'
dumpe2fs 1.35 (28-Feb-2004)
Block size: 4096
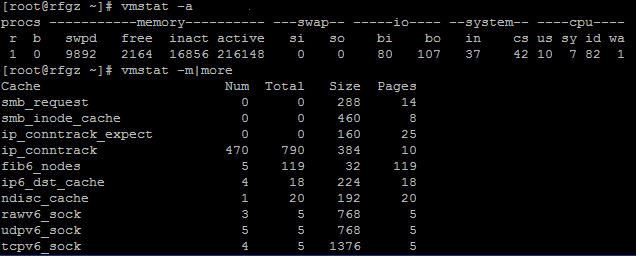
四、Vmstat
Vmstat命令提供了对进程、内存、页面I/O块和CPU等信息的监控,vmstat可以显示检测结果的平均值或者取样值,取样模式可以提供一个取样时间段内不同频率的监测结果。

注:在取样模式中需要考虑在数据收集中可能出现的误差,将取样频率设为比较低的值可以尽可能的减小误差的影响。
下面介绍一下各列的含义
引用
·process(procs)
r:等待运行时间的进程数量
b:处在不可中断睡眠状态的进程
w:被交换出去但是仍然可以运行的进程,这个值是计算出来的
·memoryswpd:虚拟内存的数量
free:空闲内存的数量
buff:用做缓冲区的内存数量
·swap
si:从硬盘交换来的数量
so:交换到硬盘去的数量
·IO
bi:向一个块设备输出的块数量
bo:从一个块设备接受的块数量
·system
in:每秒发生的中断数量, 包括时钟
cs:每秒发生的context switches的数量
·cpu(整个cpu运行时间的百分比)
us:非内核代码运行的时间(用户时间,包括nice时间)
sy:内核代码运行的时间(系统时间)
id:空闲时间,在Linux 2.5.41之前的内核版本中,这个值包括I/O等待时间;
wa:等待I/O操作的时间,在Linux 2.5.41之前的内核版本中这个值为0
Vmstat命令提供了大量的附加参数,下面列举几个十分有用的参数:
引用
·m:显示内核的内存利用率
·a:显示内存页面信息,包括活跃和不活跃的内存页面
·n:显示报头行,这个参数在使用取样模式并将命令结果输出到一个文件时非常有用。例如root#vmstat –n 2 10以2秒的频率显示10输出结果
·当使用-p {分区}时,vmstat提供对I/O结果的统计

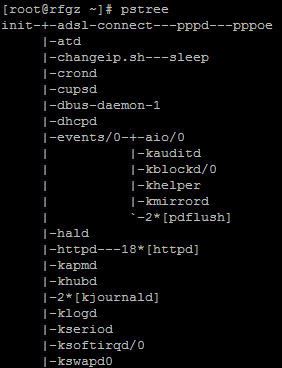
五、ps和pstree
ps和pstree命令是系统分析最常用的基本命令,ps命令提供了一个正在运行的进程的列表,列出进程的数量取决于命令所附加的参数。例如ps –A 命令列出所有进程和它们相应的进程ID(PID),进程的PID是使用其他一些工具之前所必须了解的,例如pmap或者renice。
在运行java应用的系统上,ps –A 命令的输出很容易就会超过屏幕的显示范围,这样就很难得到所有进程的完整信息。这时,使用pstree命令可以以树状结构来显示所有的进程信息并且可以整合子进程的信息。Pstree命令对分析进程的来源十分有用。
六、Numastat
随着NUMA架构的不断发展,例如eServer xSeries 445及其后续产品eServer xSeries 460,现在NUMA架构已经成为了企业级数据中心的主流。然而,NUMA架构在性能调优方面面临了新的挑战,例如内存分配的问题在NUMA系统之前并没人感兴趣,而Numastat命令提供了一个监测NUMA架构的工具。Numastat命令提供了本地内存与远程内存使用情况的对比和各个节点的内存使用情况。Numa_miss列显示分配失败的本地内存,numa_foreign列显示分配远程内存(访问速度慢)信息,过多的调用远程内存将增加系统的延迟从而影响整个系统的性能。使运行在一个节点上的进程都访问本地内存将极大的改善系统的性能。
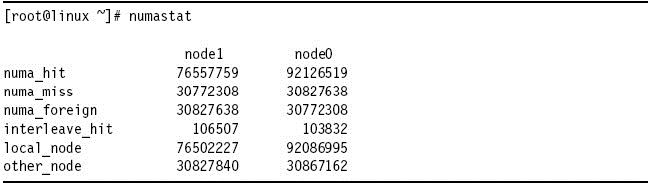
※我使用的系统不支持NUMA架构,此图为原文档截图。
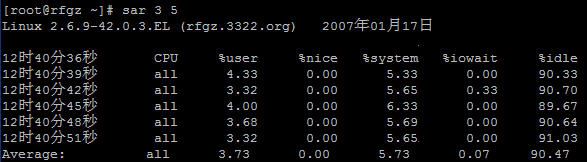
七、sar
sar程序也是sysstat安装包的一部分。sar命令用于收集、报告和保存系统的信息。Sar命令由三个应用组成:sar,用与显示数据;sa1和sa2,用于收集和存储数据。默认情况下,系统会在crontab中加入自动收集和分析的操作:
引用
[root@rfgz ~]# cat /etc/cron.d/sysstat
# run system activity accounting tool every 10 minutes
*/10 * * * * root /usr/lib/sa/sa1 1 1
# generate a daily summary of process accounting at 23:53
53 23 * * * root /usr/lib/sa/sa2 -A
sar命令所生成的数据保存在/var/log/sa/目录下,数据按照时间保存,可以根据时间来查询相应的性能数据。
你也可以使用sar在命令行下得到一个实时的执行结果,收集的数据可以包括CPU利用率、内存页面、网络I/O等等。下面的命令表示用sar执行5次,间隔时间为3秒:
八、free
free命令显示系统的所有内存的使用情况,包括空闲内存、被使用的内存和交换内存空间。Free命令显示也包括一些内核使用的缓存和缓冲区的信息。
当使用free命令的时候,需要记住linux的内存结构和虚拟内存的管理方法,比如空闲内存数量的限制,还有swap空间的使用并不标志一个内存瓶颈的出现。

Free命令有用的参数:
引用
·-b,-k,-m和-g分别按照bytes, kilobytes, megabytes, gigabytes显示结果。
·-l区别显示low和high内存
·-c {count}显示free输出的次数
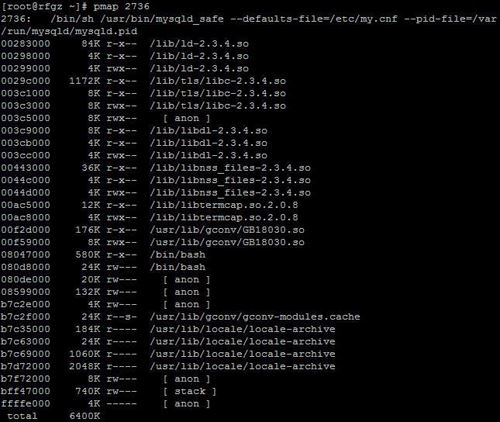
九、Pmap
pmap命令显示一个或者多个进程使用内存的数量,你可以用这个工具来确定服务器上哪个进程占用了过多的内存从而导致内存瓶颈。
十、Strace
strace截取和记录进程的系统调用信息,还包括进程接受的命令信号。这是一个有用的诊断和调试工具,系统管理员可以通过strace来解决程序上的问题。
命令格式,需要指定需要监测的进程ID。这个多为开发人员使用。
strace -p <pid>
十一、ulimit
可以通过ulimit来控制系统资源的使用。请看以前的日志:使用ulimit和proc去调整系统参数
十二、Mpstat
mpstat命令也是sysstat包的一部分。Mpstat命令用于监测一个多CPU系统中每个可用CPU的情况。Mpstat命令可以显示每个CPU或者所有CPU的运行情况,同时也可以像vmstat命令那样使用参数进行一定频率的采样结果的监测。

十三、附录
本文截取和修改自IBM的红皮书Tuning Red Hat Enterprise Linux on IBM eServer xSeries Servers。
- 详解:床头放什么会对我们有影响
- 3DMAX光滑组、网格平滑和涡轮平滑几个命令概念详解
- Maya如何渲染巨型尺寸的图像?maya渲染大图的切分方法详解
- 3DMAX游戏角色写实详解
- 新房装修风水禁忌详解
- 2020年十大最新款游戏笔记本电脑,ROG 轻薄2k屏游戏本性能强悍
- 2020年旗舰机性能排行榜,苹果iPhone 11、三星 Galaxy S20很不错
- 华为matebook14锐龙版R5性能如何 值得入手吗
- 十大塑料地板品牌,LGHausys、Gerflor洁福塑料地板环保性能高
- RedmiBook 16性能如何 红米16笔记本详细体验
- 荣耀MagicBook Pro值得入手吗 荣耀MagicBook Pro笔记本性能全面评测
- RedmiBook14增强版性能好不好 RedmiBook14增强版性能+拆解全面评测